第 8 章 中央处理器
第一讲 中央处理器概述
指令执行过程
组成指令功能的四种基本操作
- 读取主存,写入寄存器(读数、取数)
- 读取寄存器,写入主存(存结果)
- 读取寄存器,写入到另一寄存器或 ALU(取数、存结果)
- 逻辑和算数运算(PC+1、计算地址、运算)
CPU 的基本组成
- 执行部件 - 数据通路(Datapath)
- ALU、GPRs、数据通路等所有执行指令的功能部件,是指令执行过程中,数据经过的路径
- 控制部件 - 控制器(Control Unit)
- 指令译码器和控制信号生成器、IR、PC,负责对指令进行译码,生成指令对应的控制信号,控制数据通路的动作
数据通路的基本结构
- 数据通路由两类元件组成
- 组合逻辑元件(操作元件)
- 时序逻辑元件(状态元件、存储元件)
- 连接方式
- 总线连接方式
- 分散连接方式
- 功能
- 进行数据存储、处理、传送
- 定义:数据通路是由操作元件和组合元件通过总线或分散链接方式,进行数据存储、处理、传送
操作元件:组合逻辑电路
加法器、算术逻辑部件、多路选择器、译码器(特指
- 均为组合逻辑电路,输出只取决于当前的输入
- 所有输入到达后,经过一定的逻辑门延时,输出端改变,并保持到下一次改变,不需要时钟信号
状态元件:时序逻辑电路
特点:
- 具有存储功能,在时钟控制下输入被写入到电路中,直到下一个时钟到达
- 输入端状态决定何时被写入,输出端状态随时可以读出 定时方式:规定信号何时写入状态元件或何时从状态元件读出
- 边沿触发(edge-triggered):值只在时钟边沿改变,每时钟周期改变一次
- 上升沿触发(rising edge)
- 下降沿触发(falling edge)
D 触发器
- 建立时间(Setup Time):边沿之前输入 D 必须稳定的时间
- 保持时间(Hold Time):边沿之后输入 D 必须保持的时间
- Clock-to-Q time(锁存延迟(Latch Prop)、触发器传播延迟):在时钟边沿,输出并不能立即变化
存储元件
- 寄存器
- 有一个写使能(Write Enable-WE)信号
- 0:时钟边沿到来时,输出不变
- 1:时钟边沿到来时,输出开始变为输入
- 若每个时钟边沿都写入,则不需要 WE 信号
- 有一个写使能(Write Enable-WE)信号
- 寄存器组
- 两个读口(组合逻辑操作)
- 一个写口(时序逻辑操作):写使能为 1 的情况下,始终边沿到来时,busW 传来的值开始被写入到 RW 指定的寄存器中
- 理想存储器(idealized memory)
- 结构
- Data Out:32 位读出数据
- Data In:32 位写入数据
- Address:读写共用一个 32 位地址
- 读操作(组合逻辑操作)
- 写操作(时序逻辑操作)
- 结构
数据通路与时序控制
- 同步系统(Synchronous system)
- 所有动作有专门的时序信号来定时
- 由时序信号规定何时发出什么动作
- 时序信号:通讯系统中用于进行同步控制的定时信号,如时钟信号
- 指令周期:取并执行一条指令的时间,每条指令的指令周期未必相同
- Cycle Time = Clk-to-Q + Longest Delay Path + Setup Time
- 约束条件:(Clk-to-Q + Shortest Deylay) > Hold Time
计算机性能与 CPU 时间
- 计算机有两种不同的性能
- Time to do the task
- 响应时间(response time)
- 执行时间(execution time)
- 等待时间或时延(latency)
- Tasks per day, hour, sec, ns ...
- 吞吐率(throughput)
- 带宽(bandwidth)
- Time to do the task
- 基本性能评价标准:CPU 的执行时间
计算机性能的测量
使用执行时间来衡量:
- 程序往往被多个程序共享使用,因此,用户感觉到的程序执行时间,并不是程序真正的执行时间
- 通常把用户感觉到的响应时间分成以下两个时间:
- CPU 时间:指 CPU 真正花在程序执行上的时间,包括:
- 用户 CPU 时间:用来运行用户代码的时间
- 系统 CPU 时间:为了执行用户程序而需要运行操作系统程序的时间
- 其他时间:指等待 I/O 操作完成或 CPU 花在其他用户程序的时间
- CPU 时间:指 CPU 真正花在程序执行上的时间,包括:
- 系统性能和 CPU 性能不等价
- 系统性能(System performace)
- CPU 性能(CPU performance)
CPU 执行时间的计算
CPI :Cycles Per Instruction
CPI 用来衡量以下各方面的综合结果:
- 指令集(ISA)
- 微体系结构
- 程序(编译器、算法)
| 指令个数 | CPI | 时钟频率 | |
|---|---|---|---|
| 编程 | X | X | |
| 编译器 | X | (X) | |
| 指令集设计 | X | X | |
| 微结构 | X | X | |
| 电路/器件工艺 | X |
CPI 的计算
假定
单靠 CPI 无法反应 CPU 性能!
早期性能指标
定点指令执行速度:
第二讲 单周期数据通路设计
实现目标概述(RV32I 中的 9 条指令)
设计处理器的步骤
ISA 确定后,进行处理器设计的大致步骤
- 分析每条指令的功能,并用 RTL(Register Transfer Language)来表示
- 根据指令的功能给出所需的元件,并考虑如何将它们互连
- 确定每个元件所需控制信号的取值
- 汇总所有指令所涉及到的控制信号,生成一张反映指令与控制信号之间的表
- 根据表得到每个控制信号的逻辑表达式,据此设计控制器电路
1-3 为数据通路设计,3-5 为控制器的设计
数据通路的实现目标包括:
- 3 条 R 型指令:
- add rd, rs1, rs2
- slt rd, rs1, rs2 (Set on Less Than)
- sltu rd, rs1, rs2 (Set on Less Than Unsigned)
- 2 条 I 型指令:
- ori rd, rs1, imm12(Or Immediate)
- lw rd, rs1, imm12(Load Word)
- 1 条 S 型指令
- sw rs1, rs2, imm12(Save Word)
- 1 条 B 型指令
- beq rs1, rs2, imm12(Branch on Equal)
- 1 条 U 型指令
- lui rd, imm20(Load Upper Immediate)
- 1 条 J 型指令
- jal rd, imm20(Jump & Link) 每条指令的第一步都是取指令并 PC+=4,I 型指令的立即数为符号扩展,即使是逻辑运算,也有符号扩展。

扩展器部件的设计
- 作用:处理立即数,结构为:
- 立即数拼接器:根据指令格式,对指令中的立即数进行拼接和符号扩展,形成 32 位立即数。
- ExtOp:控制选择和输入指令相匹配的立即操作数输出
- 电路实现:
- 直接连导线即可实现拼接和符号扩展的功能
- 使用可编程逻辑器件也可以实现这些功能
- 注意:
- B-型和 J-型指令的最后一位会在符号扩展时补 0,等价于进行了左移 1 位的操作
算术逻辑部件的设计
- 作用:实现 add, or, slt, sltu, srcB 操作
- 功能:
- ALUctr = add 时,OPctr = 00
- ALUctr = or 时,OPctr = 01
- ALUctr = scrB 时,OPctr = 10(此时是直接输出操作数 B)
- ALUctr = slt/sltu 时,Opctr = 11
- 对应指令:
- add, lw, sw, jal 指令:使用 add 操作
- ori 指令:使用 or 操作
- slt, sltu 指令:分别对应 slt 和 sltu 操作
- lui 指令:使用 srcB 操作(电路设计导致)
- beq 指令:使用 sub 操作判断 0
- 电路实现:使用组合逻辑电路即可实现
取指令部件的设计
- 作用:每条指令都有的公共操作:
- 取指令:M\[PC]
- 更新 PC:PC ← PC + 4
- 转移时,PC 内容再次被更新为“转移目标地址”
- 结构:
- 电路实现:使用时序逻辑电路
R-型指令的数据通路
- add, slt, slut 功能:R[rd] ← R[rs1] op R[rs2]
- 操作:
- 根据 PC 读取指令
- 将以下字段送控制器:
- 操作码 opcode
- 功能码 funct3
- 将以下字段送 GPRs:
- rs1 送 Rs1 输入端
- rs2 送 Rs2 输入端
- rd 送 Rd 输入端
- 有关控制器信号:
- RegWr:寄存器写入控制
- ALUctr:ALU 操作控制
I-型指令的数据通路
- ori 功能:R[rd] ← R[rs1] or SEXT(imm12)
- 有关控制器信号:
- RegWr:寄存器写入控制
- ALUctr:ALU 操作控制
- ALUBSrc:操作数 B 的选择
- ExtOp:扩展器操作数控制,为 immI
U-型指令的数据通路
- lui 功能:R[rd] ← imm20||000H
- 操作:直接将扩展器的结果输出给 R[Rd]
- 有关控制器信号:
- RegWr:寄存器写入控制
- ALUctr:ALU 操作控制,为 srcB
- ALUBSrc:操作数 B 的选择
- ExtOp:扩展器操作数控制,为 immU
- (如果需要使用到 PC,则还有一个额外电路控制 PC 的输入)
Load/Store 指令的数据通路
- lw 指令(I-型)功能:R[rd] ← M[R[rs1]] + SEXT(imm12)
- sw 指令(S-型)功能:M[R[rs1]]+SEXT(imm12) ← R[rs2]
- 有关控制器信号:
- RegWr:寄存器写入控制
- ALUctr:ALU 操作控制,为 srcB
- ALUBSrc:操作数 B 的选择
- ExtOp:扩展器操作数控制,为 immI/immS
- MemWr:存储器写入控制
- MemtoReg:控制寄存器写入来源
B-型指令的数据通路
- beq 功能:条件跳转
if(R[rs1] == R[rs2])
PC ← PC + (SEXT(imm12)×2)
else PC ← PC + 4
- 有关控制器信号:
- Branch:接入取指令部件的下地址逻辑中,用来控制跳转
- ExtOp:扩展器操作数控制,为 immB
- 下地址逻辑:由多路选择器、加法器、与门实现
J-型指令的数据通路
- jal 功能:PC ← PC + SEXT(imm[20:1]<<1); R[rd] ← PC + 4
- 有关控制信号:
- Jump:接入下地址逻辑中,用来控制跳转
- ExtOp:扩展器操作数控制,为 immJ
- 地址的计算:
- PC+SEXT(imm[20:1]<<1) 在下地址逻辑的加法器中完成
- R[rd] ← PC+4 在算术逻辑部件中实现
- ALUBSrc 因此扩展成两位,结果一般存储在 x0 中
完整的单周期数据通路
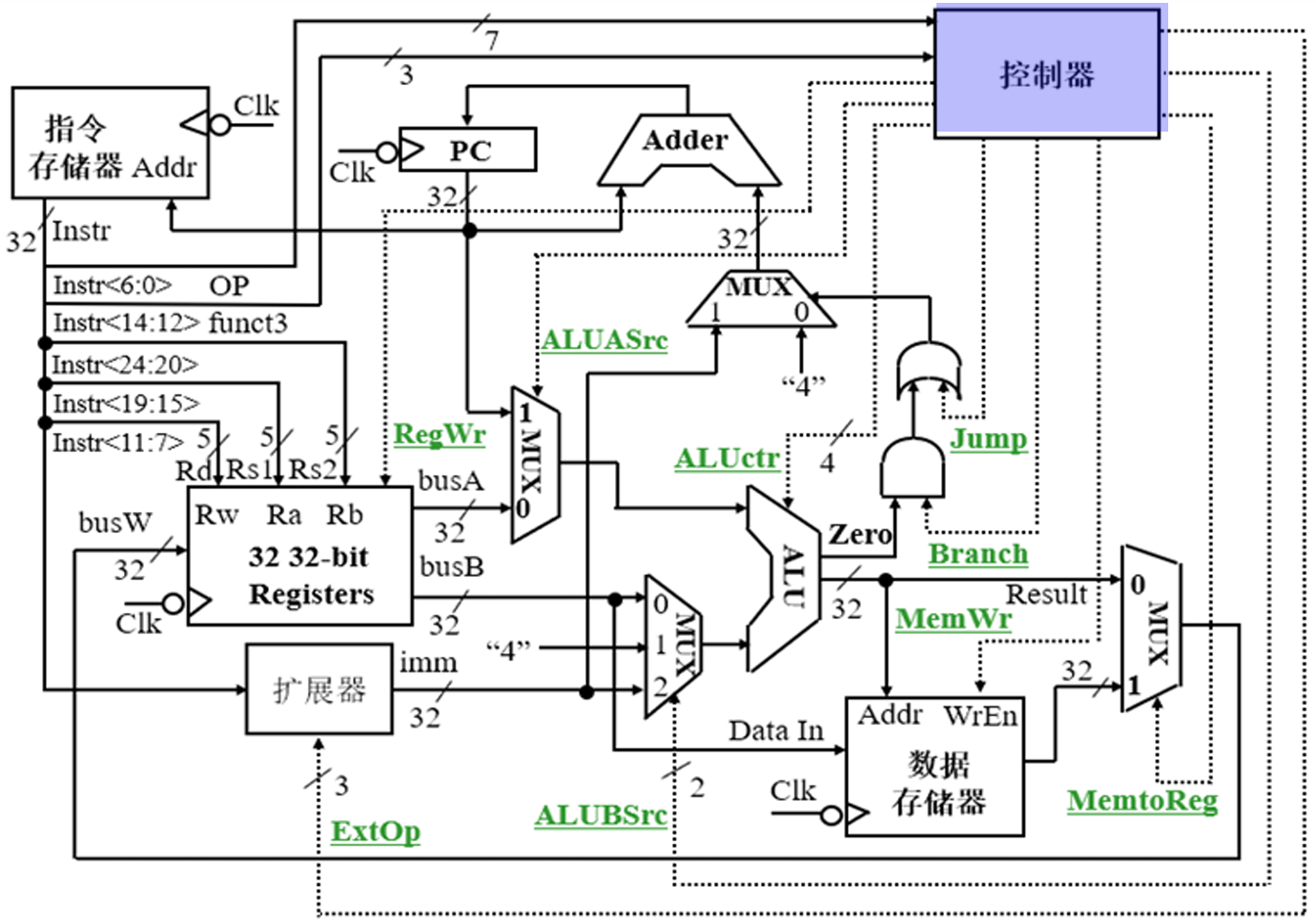
第三讲 单周期控制器的设计
指令开始时取指令部件中的动作
取指令:Instruction ← M[PC]
- 对所有指令都相同
- 新指令取出后还没有译码,所以控制信号的值还是原来指令的旧值
指令译码后 R-型指令操作过程
| RegWr | ExtOp | ALUctr | ALUASrc | ALUBSrc | |
|---|---|---|---|---|---|
| add rs1, rs2, rd | 1 | x | add | 0 | 0 |
| slt rs1, rs2, rd | 1 | x | slt | 0 | 0 |
| sltu rs1, rs2, rd | 1 | x | sltu | 0 | 0 |
| Jump | Branch | MemWr | MemtoReg | |
|---|---|---|---|---|
| add rs1, rs2, rd | 0 | 0 | 0 | 0 |
| slt rs1, rs2, rd | 0 | 0 | 0 | 0 |
| sltu rs1, rs2, rd | 0 | 0 | 0 | 0 |
- I-型,U-型与 R-型时序类似,只有控制信号上的差异
指令译码后 Load/Store 指令操作过程
- lw 指令涉及访问主存,消耗的时间较大
时钟周期的确定
- 找数据通路中的关键路径
第四讲 多周期处理器的设计
多周期处理器思想
- 单周期处理器时钟周期必须以最复杂的指令所需时间为准,过长
- 解决思路:
- 将指令执行分为多个阶段,每个阶段在每个时钟周期内完成
- 时钟周期以最复杂的阶段所花时间为准
- 尽量分成大致相等的若干阶段
- 规定每个阶段最多只能完成一次访存或一次 GPRs 读写或一次 ALU 运算
- 每步都设置状态单元,每步执行结果都在下个时钟开始保存到相应单元
- 将指令执行分为多个阶段,每个阶段在每个时钟周期内完成
- 多周期处理器的好处:
- 时钟周期短
- 不同指令所用周期数可以不同,如 Load:5 周期,Jump:3 周期
- 允许功能部件在一条指令执行过程中被重复使用,如
- Adder + ALU(多周期时只用一个 ALU,在不同周期可重复使用)
- Inst. / Data mem(多周期时合用,不同周期中重复使用)
实现举例:简单指令系统
只有一种指令格式:
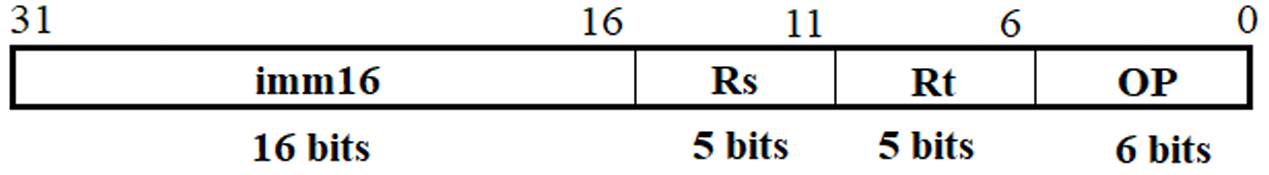
可实现如下功能:
- R-型:R[Rt]←R[Rs] op R[Rt],两个寄存器内容运算,结果送寄存器
- I-型运算:R[Rt]←R[Rs] op EXT[imm16],寄存器内容和立即数计算
- Load:R[Rt]←M[R[Rs]+imm16],地址为寄存器内容加立即数
- Store:M[R[Rs]+SEXT[imm16]]←R[Rt],地址为寄存器内容加立即数
- Jump:PC←PC+SEXT[imm16],跳转目标地址为PC内容加立即数 得到有限状态机:
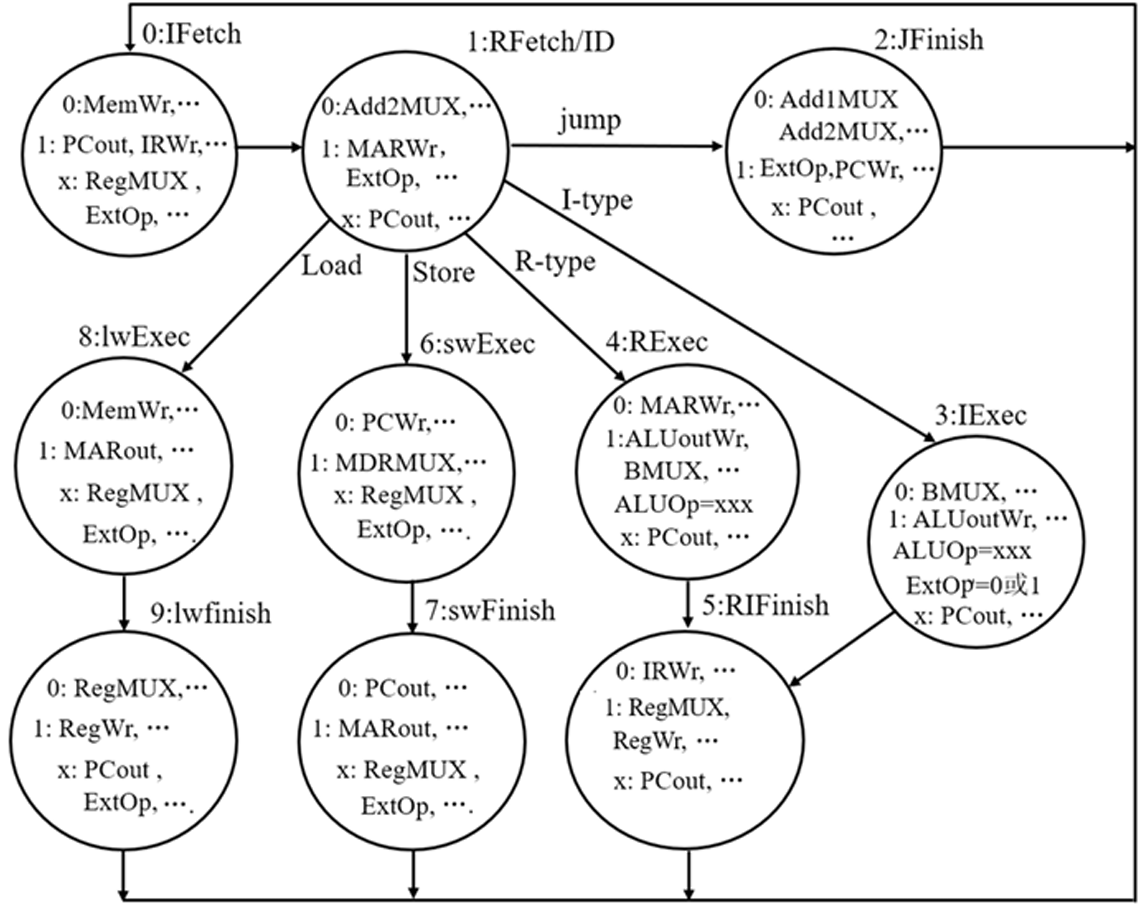
多周期控制器的实现
多周期控制器无法用组合逻辑电路设计出,应当是一个时序逻辑电路。实现方式有两种:
- 用硬连线路(PLA)实现
- 初始表示(有限状态机)→顺序控制(次态方程)→逻辑表示(逻辑函数)→实现技术(PLA+触发器)
- 用 ROM 存放微程序实现
- 初始表示(微程序)→顺序控制(微程序计数器+ROM 存储器)→逻辑表示(真值表)→实现技术(ROM)
硬连线控制器
- 优点:速度快,适合简单或规整的指令系统
- 缺点:很难处理复杂指令系统,结构复杂,实现困难;修改、维护不易;灵活性差。有些比较复杂的逻辑无法用有限状态机描述。
微程序控制器
- 基本思想:仿照程序的设计方法,编制每个指令对应的微程序
- 输入:指令、条件码;输出:控制信号(微命令)
带异常处理的处理器设计
- 遇到异常时的基本处理:
- 关中断(“中断/异常允许”状态位清零):使处理器处于“禁止中断”状态,以防止新异常(或中断)破坏断点、程序状态和现场(指的是通用寄存器的值)
- 保护断点和程序状态:将断点和程序状态保存到堆栈或特殊的寄存器中,即:
- PC→栈或专门存放断点的寄存器。
- PSWR→栈或 EPSWR(专门保存程序状态的寄存器)
- PSW(程序状态字):包括条件码、中断码、状态位等
- 识别异常状态:分为软件识别和硬件识别(向量中断方式)
- 软件识别:设置一个异常原因寄存器 (如 RISC-V 中的 Cause 寄存器),用于记录异常原因。操作系统使用一个统一的异常处理程序,按照优先级顺序查询异常状态寄存器,识别出异常事件。
- 硬件识别(向量中断):每个异常和中断都有一个异常/中断号,据此号,到中断向量表(中断描述符表)中读取对应的具体的中断服务程序的入口地址。
举例:多周期处理器的异常和中断处理
- 引入两个寄存器:
- EPC:32 位,存放断点(异常处理后返回到的指令地址)
- 写入 EPC 的断点可能是正在执行的指令的地址,也可能是下一条指令的地址。前者需要 PC-4,后者直接送 PC
- Cause:32 位,记录异常原因
- EPC:32 位,存放断点(异常处理后返回到的指令地址)
- 引入两个写使能信号:
- EPCWr:保存断点时该信号有效
- CauseWr:在处理器发现异常时,该信号有效
第五讲 流水线数据通路和控制
使用流水线数据通路设计可以大幅提高多条指令的执行时间,但也会带来一些设计上的复杂性、冲突、竞争等。
流水线方式下,单条指令执行时间不能缩短(反而可能会提升),但能大大提高指令吞吐率。