Lecture 3 - Loss Function and Optmizatoin
Loss Function
- 损失函数的作用是用来量化权重矩阵
- 假设存在数据集:
Muliple SVM Loss
- 设
其中的
据其形状,这种损失函数也被称作“Hinge Loss”
初始损失
通过随机初始化
Regularization
- 通过引入 Regularization Loss Fucntion
- 其中的
Occam's Razor
Among competing hypothese, the simplest is the best.
- 常用的正则函数有:
- L2 regularization:
- L1 regularization:
- Elastic net (L1+L2):
- Max norm regularization
- Dropout
- Fancier: Batch regularization, stochastic depth
- L2 regularization:
L1 和 L2 的对比
L1 和 L2 相比,L1 会更倾向于选择稀疏矩阵,而 L2 更倾向于选择分布均匀的矩阵。 例如,输入
Softmax Loss (Multinomial Logistic Regression)
- 通过
- 这样处理使得选择任意类别的概率
- 我们希望
- Softmax 损失函数也被称作“Cross-entropy Loss”
初始损失
通过随机初始化
- 对比 SVM Loss 和 Softmax Loss,前者只需非正确类别的分数低于正确类别一定距离,就判定为无损失;而后者总是希望将所有概率密度都堆积在正确类别上,这会导致其希望正确类别的分数趋于正无穷,而错误类别的分数趋于负无穷,在有限精度下无法使损失函数真正为 0
Optimization
- Optimization 的目的就是为了找到使得损失函数
- 完整的损失函数的一般形式:
- 其中的
- 实际问题中,
- 因此,在实际问题中,往往使用迭代法去求解损失函数的最小值
- 实际问题中,
Gradient(梯度)
- 多元函数的梯度是一个向量,其每一维度的值是函数对相应元的偏导数。某点处的梯度指向的是多维空间中,函数增速最快的方向。因此,负梯度指向的方向就是函数减少最快的方向。
- 梯度也是多元函数在某点处的线性一阶近似。
有限差分法
- 通过有限差分计算梯度,就是在利用偏导数的极限定义
- 有限差分法的时间复杂度为
微积分
- 通过求解梯度的解析式,可以极大提高计算梯度的精度和效率,直接根据输入计算一次函数求得梯度
使用有限差分验证解析式
将通过有限差分法得到的梯度与使用自己推导出来的解析式计算出来的梯度进行对比,如果偏差过大,则意味着可能出现了推导错误
Gradient Descent(梯度下降)
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad
step_size或者也称作learning_rate,是每次沿着负梯度方向前进的距离,是一个非常重要的超参数
Stochastic Gradient Descent
- 在实际问题中,数据集可能会非常大,这将导致计算损失函数变得非常慢。因此,我们会采用随机采样的方式,获取估计的梯度,据此进行梯度下降
while True:
data_batch = sample_training_data(data, minibatch_size)
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad
minibatch_size即为采样数,是一个超参数,一般取 32、64、128、256 等
Feature
- 对于某些问题,我们无法直接对其进行线性分类,但我们可以通过先将问题转化为可线性分类的问题,再进行处理的方式使其可以应用线性分类解决。
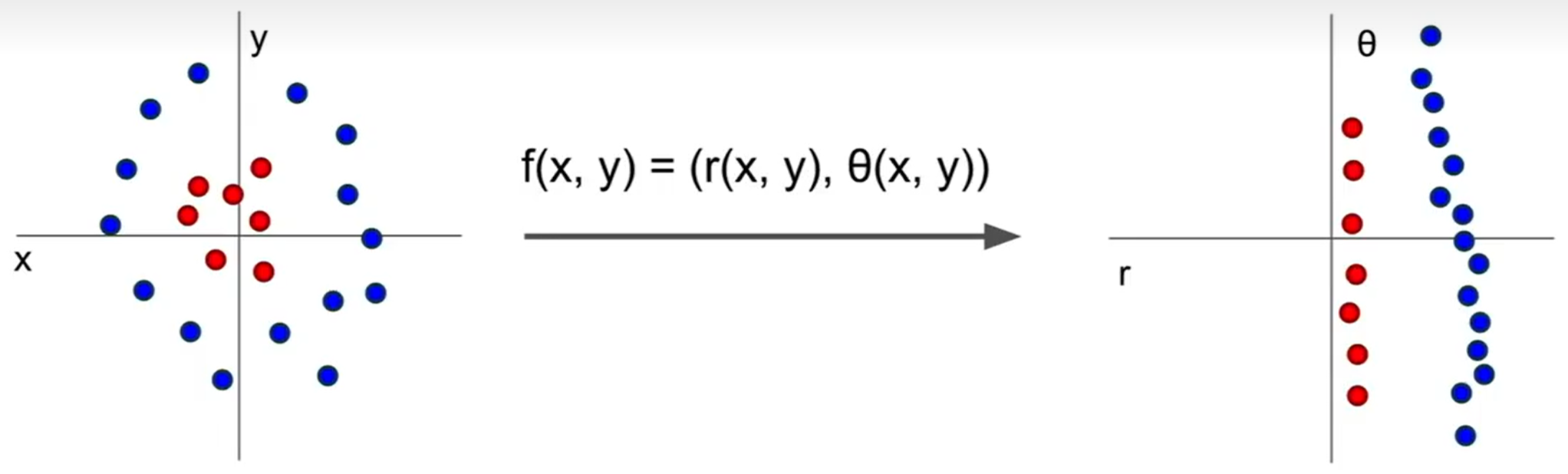
Histogram of Oriented Gradiants (HoG)
- 定向梯度直方图:模仿人类识别物体时更加关注物体边缘,提出通过计算边缘方向的方式,捕获图像特征
- 研究者将图像划分成
- 如果将图像分成

Bag of Words
- 模仿 NLP 中的词袋模型,先将图片切块,通过 KNN 获取若干个聚类中心,将这些中心标记为“词”,再将图片根据这些词取直方图,最后使用线性分类器进行分类