Lecture 4 - Backpropagation and Neural Networks
Backpropagation
Computational Graphs
- 以图的形式呈现计算过程,根据此计算过程,可以应用链式法则求解梯度
Backpropagation
- 计算图上的每一条链,都可以通过链式法则从后向前计算出前一个节点的梯度
- 使用这种方法,计算整体梯度被拆分成了计算若干个局部梯度,从而使得求解复杂函数的梯度变得可行
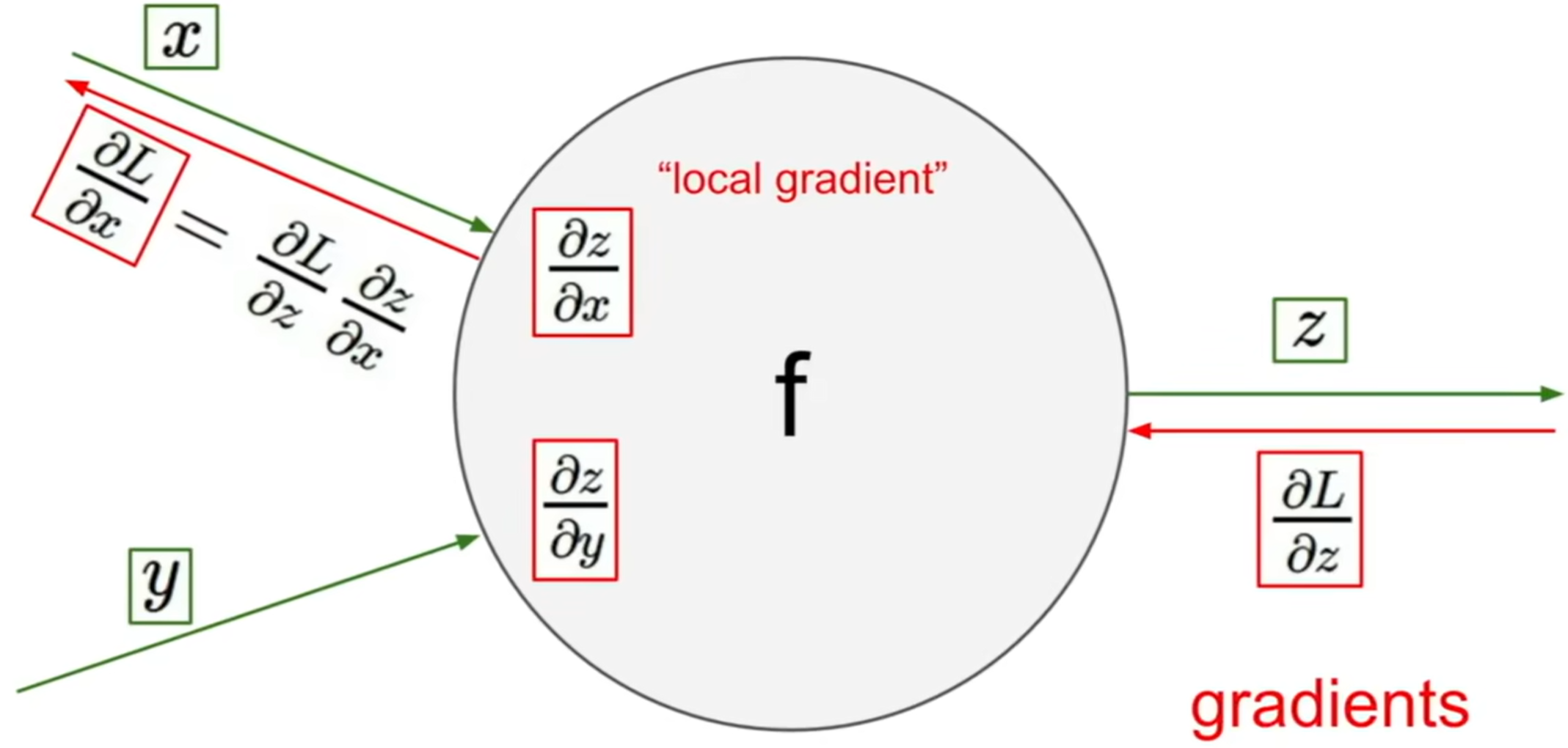
- 使用这种方法,我们可以将常用的函数的计算节点封装,从而实现直接调用,简化计算,例如:
- Sigmoid Gate:
- Max Gate: 大的一方的局部梯度为 1,小的一方局部梯度为 0
- Sigmoid Gate:
- 不同的函数可以起到不同的作用:
- Add Gate: gradient distributor,即
- Max Gate: gradient router,即
- Mul Gate: gradient switcher,即
- Add Gate: gradient distributor,即
Vectorized Operations
- 当输入为向量的时候,输出的偏导数就变成了雅可比矩阵,而雅可比矩阵的大小是输入向量维数×输出向量维数的,这就会导致计算非常的低效
- 在实际使用中,往往会对雅可比矩阵进行化简,直接找出右侧梯度输入和左侧变量输入与局部梯度的关系表达式,例如:
检查
梯度的形状和左侧输入的形状是完全相同的
- 若输入为矩阵
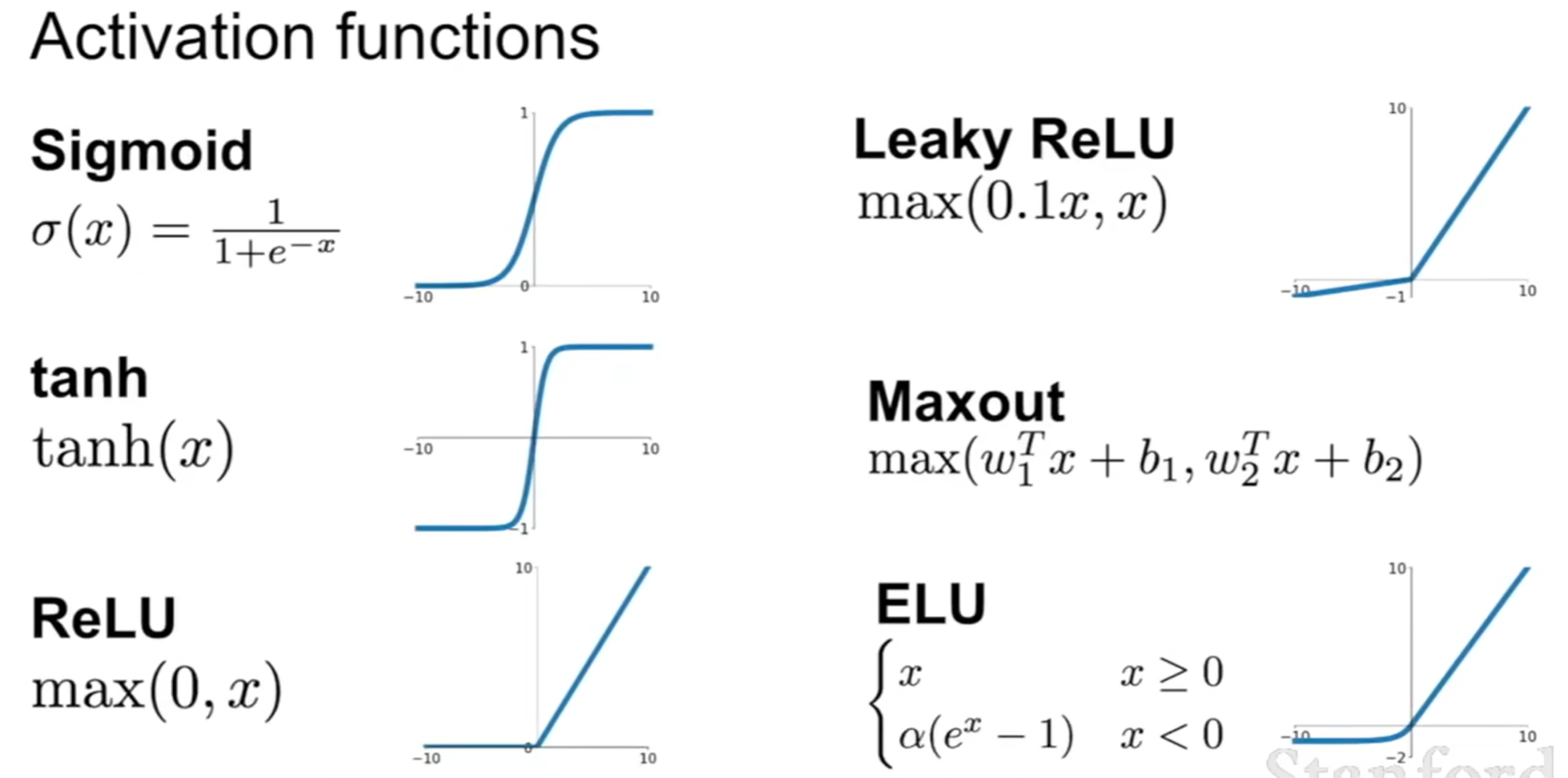
Neural Networks
- 通过线性层的相乘,组成更加复杂的非线性函数