Lecture 6 - Training Neural Networks
Activation Function
Sigmoid
特点
- 将输出的数值压缩到
- 具有非常类似神经元达到阈值就激活的机制
问题
- 当
- 输出不是以
- 若后续出现
- 若后续出现
tanh
特点
- 将输出数值压缩到
- 输出以
问题
- 饱和神经元同样会导致梯度消失
ReLU (Recititied Linear Unit)
特点
- 在输入为正数时不存在“饱和”的情况
- 比 Sigmoid 和 tanh 收敛更快(大约 6 倍)
- 与生物学上的神经元机制更加相似
问题
- 输出不以
- 当
Leaky ReLU
特点
- 不会“饱和”
- 计算较为高效
- 比 simgoid/tanh 收敛更快(大约 6 倍)
- 不会出现梯度消失的情况
Paramatrix Rectificer (PReLU)
- 在 Leaky ReLU 的基础上,令
- 然后使用反向传播更新
Exponential Linear Units (ELU)
特点
- 具有 ReLU 的所有优点
- 接近
- 与 Leaky ReLU 相比,负饱和状态增加了对噪声的容错性
问题
- 需要计算
Maxout
特点
- 是 ReLU 和 Leaky ReLU 的一般化
- 不会饱和,不会梯度消失
问题
- 每个神经元的参量会加倍
实际使用
- 一般使用 ReLU,需要小心学习率的设计
- 尝试使用 Leaky ReLU/Maxout/ELU
- 使用 tanh 但别太抱太高期望
- 别使用 Sigmoid
Data Preprocessing
zero-centered (
- 防止输入全正导致的梯度全正降低训练效率
- 对训练集和测试集需要偏移相同的均值(将根据训练集获取的均值应用到测试集上)
- 常用的两种均值:
- 平均图像:宽×高×通道大小的数组,图像直接减去这个数组
- 通道平均值:每个通道一个均值,图像的每个像素的每个通道分别减去对应的均值
normalized (规范化)
- 使得不同维度对结果的影响能力相同
- 在图像处理中使用得较少
PCA(主成分分析)
- 降低数据维度
- 在图像处理中使用得较少
Whitening
- 在图像处理中使用得较少
Weight Initialization
Small Random Numbers
- 使用
- 对于较小的神经网络是有效的,但对于多层的神经网络会出现问题
- 由于将权重都初始化为了较小的数,在正向传播过程中,由于输出会由于不断乘权重迅速减小,很快就会变为
- 反向传播的时候同理,梯度一样会迅速的消失
- 但是将权重变大,也面临着神经元“饱和”的情况,同样会导致梯度的消失
- 由于将权重都初始化为了较小的数,在正向传播过程中,由于输出会由于不断乘权重迅速减小,很快就会变为
Xavier Initialization
np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)- 核心思想是希望输入的方差和输出的方差相同
- 当使用了 ReLU 时,这种方法会失效,因为 ReLU 会强行使得负的一半输入失效
- 此时使用
np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2),即直接假设有一半的输入会失效,可以解决这个问题
- 此时使用
Batch Normalization
- 基本思想是迫使激活函数(输出)符合高斯分布,使得对于每一层的输入,都能做到符合高斯分布
- Batch Normalization 通常会在 Fully Connected Layer 或 Convolutional Layer 之后,因为这两个层进行的变换往往会使得输出不符合高斯分布
- 注意,对卷积层的批次归一化要考虑同时对每一张激活图的归一化和对每一个像素(多张图)的归一化
- 通过设置变换参数,可以对归一化后的参数再进行变换,以应对更加复杂的实际情况,调整饱和度(
Babysitting The Training Process
- Data preprocessing
- Choose the architecture
- Initialize the neural network
- Sanity check:检查运行结果是否符合预期
- 根据初始随机权重和随机输入的分布特征(例如以 0 为均值的高斯分布),估算出输出的期望值,与实际输出进行对比,从而确定网络结构是否正确
- 取较小的样本量,进行训练,看是否可以达到 100%的正确率(在较小样本量的情况下,精准拟合是可能的,如果达不到,则需检查是否出现了 BUG)
- Training
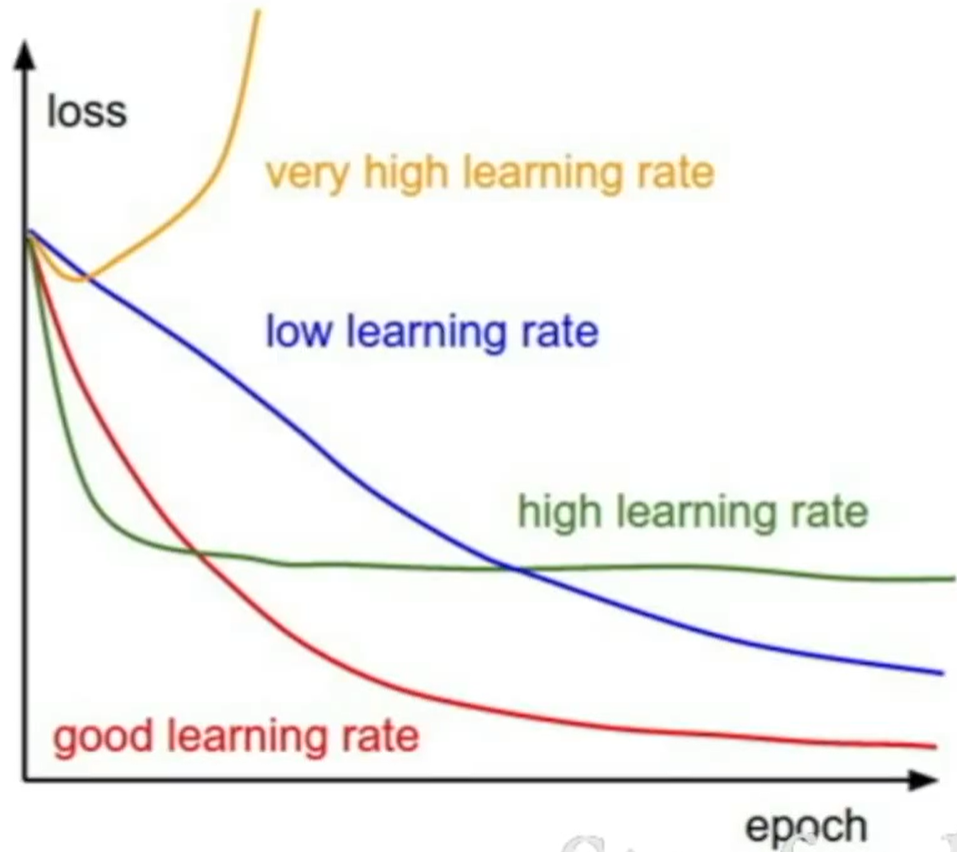
- learning rate:通常在
- 学习率太大的时候,容易出现 NaN
- learning rate:通常在
Hyperparameter Optimization
- Cross-validation strategy:通过训练找到最合适的超参数
- Random Search vs. Grid Search:使用随机搜索会更加好一些,因为在单一维度上其能够尝试到更多的取值
梯度爆炸
当某次训练的开销是一般训练开销的 3 倍以上时,很可能出现了梯度爆炸的情况,应及时停止训练,调整超参数
- Monitor and visualize the accuracy
- 通过训练集和验证集的正确率曲线,可以直观看出模型是否存在过拟合的情况
- 通过损失函数值关于 epoch 的变化,可以看出学习率是否可能导致梯度爆炸